ベイズ勉強会 Part 1 ベイズ推論のワークフロー
ベイズ推論の一連の流れを整理する。

ベイズ勉強会資料は『ベイズ推論による機械学習入門』1を元に、途中式計算をできるだけ省略せずに行ったものです。
Important: ベイズ推論の共通するワークフロー
- 観測データ$\mathcal{D}$と観測されていない未知の変数$\mathbf{X}$の同時分布$p(\mathcal{D}, \mathbf{X})$を構築
- 事後分布$p(\mathbf{X}|\mathcal{D}) = \frac{p(\mathcal{D}, \mathbf{X})}{p(\mathcal{D})}$を求める。
今回はさらに事後分布を用いて予測分布を計算するところまでを見る。
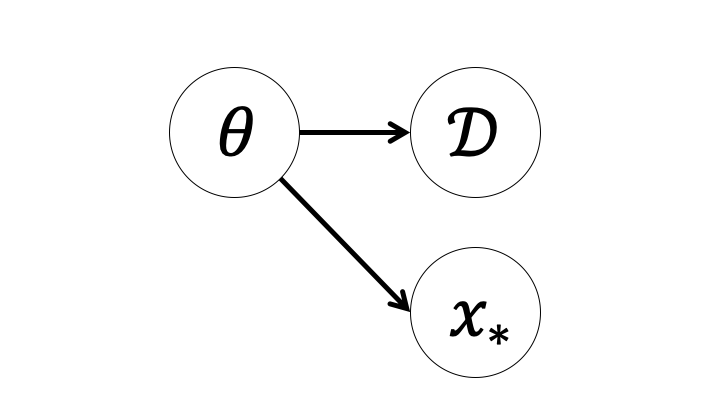
Note: $p(\theta)$は2個必要なのではないかと思うかもしれない。サイコロの目によって動きが決まる駒が2つあり、同時に動かす状況を考えよう。コマの動きを決めるのにサイコロを振る回数は1回である。
Note: $p(\mathcal{D}|\theta)$の部分はパラメタからデータが生成される過程を記述している。これを$\theta$の関数として見た場合尤度関数と呼ぶ。この尤度関数を最大化する$\theta$を$\theta$の予測値とする方法を最尤推定という。
Note: $p(\theta)$を事前分布という。同時確率は尤度関数×事前分布の形で書くことができる。
Note: ベイズの定理から$p(\theta|\mathcal{D}) = \frac{p(\mathcal{D}|\theta)p(\theta)}{p(\mathcal{D})}$となることを用いた。
Note: $p(\theta|\mathcal{D})$を最大化する$\theta$を$\theta$の予測値とする方法を事後確率最大化推定(MAP推定)と呼ぶ。